Towards Streaming Synchronized Spatial Audio Generation via Autoregressive Diffusion Transformer
Abstract
Real-time and accurate spatial audio generation is pivotal for delivering an immersive experience. However, existing spatial audio synthesis technologies are often encumbered by a tradeoff between generation quality and high inference latency, as well as difficulty in capturing precise spatial information from multimodal inputs. To address these challenges, we propose SwanSphere, a unified streaming framework for high-fidelity spatial audio generation from panoramic videos and text prompts. SwanSphere mainly makes the following contributions: 1) We introduce a causal autoregressive diffusion transformer architecture that enables streaming high-quality spatial audio generation. 2) We design a Spatial Video–Audio Contrastive (SVAC) learning strategy to align the video encoder with the acoustic domain, and further employ a multi-objective online direct preference optimization(ODPO) scheme, resulting in strong spatial perception and robust multimodal spatial audio synthesis. 3) To alleviate the current scarcity of spatial audio datasets, we also develop an automated annotation pipeline for generating detailed spatial captions. Experimental results demonstrate that SwanSphere achieves superior performance in both video-to-spatial and text-to-spatial audio generation tasks.
Overview
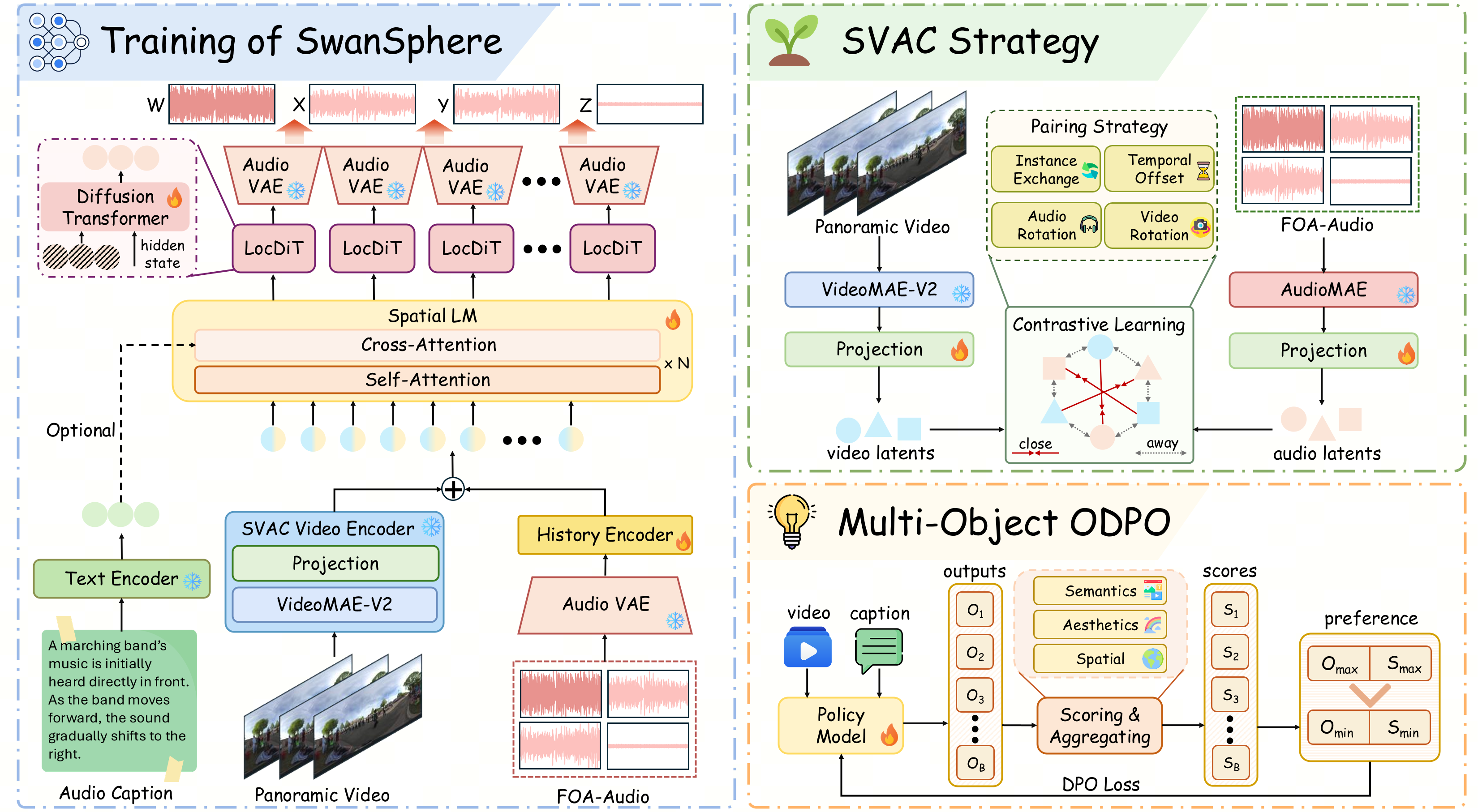
Overview of the SwanSphere framework. The left side illustrates the training pipeline based on the teacher forcing strategy, which supports both video and textual modalities during training. The upper-right section details our SVAC (Spatial Video-Audio Contrastive Learning) strategy for enhancing the Video Encoder’s alignment capability. The lower-right section introduces the Multi-Objective Preference Alignment post-training pipeline of SwanSphere.